SELECT문
- 관계 데이터베이스에서 정보를 검색하는 SQL문
- 관계 대수의 실렉션과 의미가 완전히 다름
- 관계 대수의 실렉션, 프로젝션, 조인, 카티션 곱 등을 결합한 것
- 관계 데이터베이스에서 가장 자주 사용됨
- 여러 가지 질의들의 결과를 보이기 위해서 그림 4.8의 관계 데이터베이스 상태를 사용함

기본적인 SQL 질의
- SELECT절과 FROM절만 필수적인 절이고, 나머지는 선택 사항

*일반 계산을 할 때는 SELECT 3+5 FROM DUAL(임의의 더미 테이블)
*WHERE절은 관계 대수의 실렉션 연산과 같은 기능
*GROUP BY 그룹으로 만들기
*HAVING절 그룹화된 집계 함수를 적용한 그룹에 대해서 조건을 줄 때 사용
*ORDER BY절 값에 따라 정렬시킴(결과 릴레이션에 적용되는 것임)
별칭(alias)
- 서로 다른 릴레이션에 동일한 이름(셀프조인과 관련된 작업 수행 시)을 가진 애트리뷰트가 속해 있을 때 애트리뷰트의 이름을 구분하는 방법
EMPLOYEE.DNO
FROM EMPLOYEE AS E, DEPARTMENT AS D
릴레이션의 모든 애트리뷰트나 일부 애트리뷰트들을 검색


상이한 값들을 검색


*DISTINCT는 튜플 전체에 적용되어 유니크한 튜플을 색출하는 것임
특정한 투플들의 검색

문자열 비교

*%여러 개(0개 이상, 없어도 됨) 문자와 매칭, _는 문자 하나와 매칭 -> 와일드 문자
다수의 검색 조건
- 아래와 같은 질의는 잘못되었음


부정 검색 조건

범위를 사용한 검색(BETWEEN은 양쪽 끝값을 포함함, inclusive)

리스트를 사용한 검색

SELECT절에서 산술 연산자(+, -, *, /) 사용

널값
- 널값을 포함한 다른 값과 널값을 +, - 등을 사용하여 연산하면 결과는 널
- COUNT(*)를 제외한 집단 함수들은 널값을 무시함
- 어떤 애트리뷰트에 들어 있는 값이 널인가 비교하기 위해서 ‘DNO=NULL’처럼 나타내면 안됨

- 다음과 같은 비교 결과는 모두 거짓
NULL > 300
NULL = 300
NULL <> 300
NULL = NULL
NULL <> NULL
- 올바른 표현

세 가지 값의 논리 (Three valued logic)
- true/false/unknown


true = 1, false = 0, unknown = 0.5
C1 AND C2 = min(C1, C2)
C1 OR C2 = max(C1, C2)
NOT(C1) = 1 ‐ C1
ORDER BY절
- 사용자가 SELECT문에서 질의 결과의 순서를 명시하지 않으면 사용자에게 제시되는 순서가 정해져 있지 않음
- ORDER BY절에서 하나 이상의 애트리뷰트 또는 표현식을 사용하여 검색 결과를 정렬할 수 있음
- SELECT문에서 가장 마지막에 사용되는 절
- 디폴트 정렬 순서는 오름차순(ASC)
- DESC를 지정하여 정렬 순서를 내림차순으로 지정할 수 있음
- 널값은 오름차순에서는 가장 마지막에 나타나고, 내림차순에서는 가장 앞에 나타남
- SELECT절에 명시한 애트리뷰트들을 사용해서 정렬해야 했으나, 최근 SQL에서는 SELECT 절에 나오지 않은 애트리뷰트도 허용함

집단 함수
- 데이터베이스에서 검색된 여러 투플들의 집단에 적용되는 함수
- 한 개의 애트리뷰트 또는 표현식에 적용되어 단일 값을 반환함
- SELECT절과 HAVING절에만 나타날 수 있음
- COUNT(*)를 제외하고는 널값을 제거한 후 남아 있는 값들에 대해서 집단 함수의 값을 구함
- COUNT(*)는 결과 릴레이션의 모든 행들의 총 개수를 구하는 반면에 COUNT(애트리뷰트)는 해당 애트리뷰트에서 널값이 아닌 값들의 개수를 구함
- 키워드 DISTINCT가 집단 함수 앞에 사용되면 집단 함수가 적용되기 전에 먼저 중복을 제거함


그룹화
- GROUP BY절에 사용된 애트리뷰트 또는 표현식에 동일한 값을 갖는 투플들이 각각 하나의 그룹으로 묶임
- 그룹화에 사용된 애트리뷰트를 그룹화 애트리뷰트(grouping attribute)라고 함
- 각 그룹에 대하여 결과 릴레이션에 하나의 투플이 생성됨
- SELECT절에는 집단 함수, 그룹화 애트리뷰트들만 나타날 수 있음
- 다음 질의는 그룹화를 하지 않은 채 EMPLOYEE 릴레이션의 모든 투플에 대해서 사원번호와 모든 사원들의 평균 급여를 검색하므로 잘못됨
SELECT EMPNO, AVG(SALARY)
FROM EMPLOYEE;


HAVING절
- 어떤 조건을 만족하는 그룹들에 대해서만 집단 함수를 적용할 수 있음
- 각 그룹마다 하나의 값을 갖는 애트리뷰트를 사용하여 각 그룹이 만족해야 하는 조건을 명시함
- 그룹화 애트리뷰트에 같은 값을 갖는 투플들의 그룹에 대한 조건을 나타내고, 이 조건을 만족하는 그룹들만 질의 결과에 나타남
- HAVING절에 나타나는 애트리뷰트는 반드시 GROUP BY절에 나타나거나 집단 함수에 포함되어야 함


집합 연산
- 집합 연산을 적용하려면 두 릴레이션이 합집합 호환성을 가져야 함
- UNION(합집합), EXCEPT(차집합), INTERSECT(교집합), UNION ALL(합집합), EXCEPT ALL(차집합), INTERSECT ALL(교집합)

조인
- 두 개 이상의 릴레이션으로부터 연관된 투플들을 결합
- 일반적인 형식은 아래의 SELECT문과 같이 FROM절에 두 개 이상의 릴레이션들이 열거되고, 두 릴레이션에 속하는 애트리뷰트들을 비교하는 조인 조건이 WHERE절에 포함됨
- 조인 조건은 두 릴레이션 사이에 속하는 애트리뷰트 값들을 비교 연산자로 연결한 것
- 가장 흔히 사용되는 비교 연산자는 =

- 조인 조건을 생략했을 때와 조인 조건을 틀리게 표현했을 때는 카티션 곱이 생성됨
- 조인 질의가 수행되는 과정을 개념적으로 살펴보면 먼저 조인 조건을 만족하는 투플들을 찾고, 이 투플들로부터 SELECT절에 명시된 애트리뷰트들만 프로젝트하고, 필요하다면 중복을 배제하는 순서로 진행됨
- 조인 조건이 명확해지도록 애트리뷰트 이름 앞에 릴레이션 이름이나 투플 변수를 사용하는 것이 바람직
- 두 릴레이션의 조인 애트리뷰트 이름이 동일하다면 반드시 애트리뷰트 이름 앞에 릴레이션 이름이나 투플 변수를 사용해야 함


최종 결과 릴레이션은 아래의 릴레이션에서 EMPNAME과 DEPTNAME을 프로젝션한 것이다.

자체 조인(self join)
- 한 릴레이션에 속하는 투플을 동일한 릴레이션에 속하는 투플들과 조인하는 것
- 실제로는 한 릴레이션이 접근되지만 FROM절에 두 릴레이션이 참조되는 것처럼 나타내기 위해서 그 릴레이션에 대한 별칭을 두 개 지정해야 함




중첩 질의(nested query)
- 질의의 WHERE 또는 FROM절에 다시 ‘(SELECT … FROM … WHERE …)’ 형태로 포함된 SELECT문 (괄호로 묶어서 표시함)
- 부질의(subquery)라고 함
- 중첩 질의를 포함하는 질의를 외부 질의라고 부름
- INSERT, DELETE, UPDATE문에도 사용될 수 있음
- 중첩 질의의 결과는 세 가지 경우가 있음
- 한 개의 스칼라값(단일 값)
- 한 개의 애트리뷰트로 이루어진 릴레이션
- 여러 애트리뷰트로 이루어진 릴레이

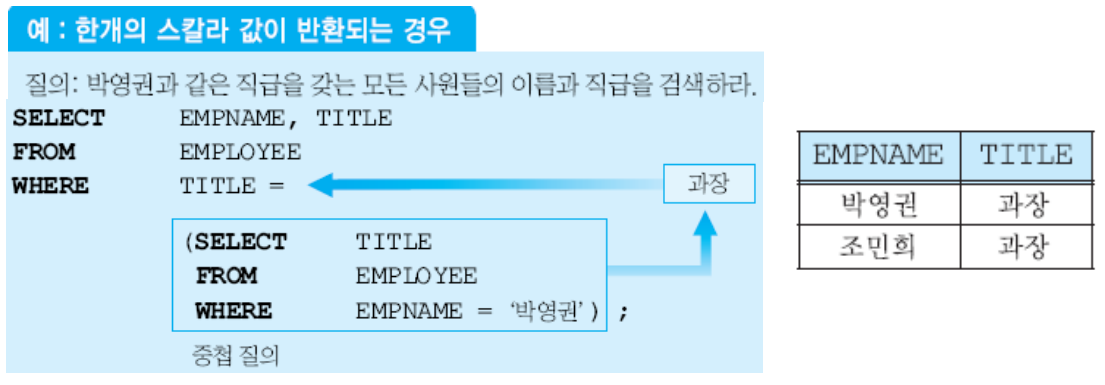
한 개의 스칼라값이 반환되는 경우
- 스칼라(scala): 컬럼 값으로 사용될 수 있는 원자 값 (atomic value)
- WHERE 절에서 상수 또는 애트리뷰트가 사용될 위치에 나타날 수 있음
한 개의 애트리뷰트로 이루어진 릴레이션이 반환되는 경우
- 중첩 질의의 결과로 한 개의 애트리뷰트로 이루어진 다수의 투플들이 반환될 수 있음
- 외부 질의의 WHERE절에서 IN, ANY(SOME), ALL, EXISTS와 같은 연산자를 사용해야 함
- IN: 한 애트리뷰트가 값들의 집합에 속하는가를 테스트
- ANY: 한 애트리뷰트가 값들의 집합에 속하는 하나 이상의 값들과 어떤 관계를 갖는가를 테스트
- ALL: 한 애트리뷰트가 값들의 집합에 속하는 모든 값들과 어떤 관계를 갖는가를 테스트
- EXISTS: 중첩 질의의 결과가 빈 릴레이션인지 여부를 검사함
- 중첩 질의의 결과가 빈 릴레이션이 아니면 참이 되고, 그렇지 않으면 거짓






여러 애트리뷰트들로 이루어진 릴레이션이 반환되는 경우
- 단일 애트리뷰트들로 이루어진 릴레이션이 반환되는 경우와 마찬가지로 IN, ANY, ALL, EXISTS 중에 하나를 사용하여 프레디킷을 만들어 사용할 수 있음
- IN, ANY, ALL을 사용하는 경우에는 결과 릴레이션과 호환되는 투플 구조를 갖는 투플을 사용해서 비교해야 함
SELECT EMPNAME
FROM EMPLOYEE E
WHERE SALARY =< 1500000 AND (E.TITLE, E.DNO) IN
(SELECT TITLE, DNO
FROM EMPLOYEE
WHERE SALARY > 1500000
);
상관 중첩 질의(correlated nested query)
- 중첩 질의의 WHERE절에 있는 프레디키트에서 외부 질의에 선언된 릴레이션의 일부 애트리뷰트를 참조하는 질의
- 중첩 질의의 수행 결과가 단일 값이든, 하나 이상의 애트리뷰트로 이루어진 릴레이션이든 외부 질의로 한 번만 결과를 반환하면 상관 중첩 질의가 아님
- 상관 중첩 질의에서는 외부 질의를 만족하는 각 투플이 구해진 후에 중첩 질의가 수행됨
- 상관 중첩 질의는 외부 질의를 만족하는 투플 수만큼 여러 번 수행될 수 있음

FROM 절에 사용된 중첩 질의
- FROM 절에 저장된 일반 테이블과 함께 중첩 질의를 사용할 수 있음
- 중첩 질의는 테이블 이름이 없으므로 alias를 사용하여 이름 부여
SELECT EMPNAME, DEPTNAME
FROM EMPLOYEE E, (SELECT DEPTNO, DEPTNAME FROM DEPARTMENT) D
WHERE E.DNO = D.DEPTNO AND TITLE = ‘과장’;'👨💻Computer Science > 데이터베이스' 카테고리의 다른 글
| [Database] 프로그램과 MYSQL 연동 시 필요한 SQL (0) | 2022.04.06 |
|---|---|
| [Database] 04 - 3 데이터 정의어와 무결성 제약조건 (0) | 2021.10.07 |
| [Database] 04 - 2 SQL 개요 (0) | 2021.10.07 |
| [Database] 04 - 1 관계 대수와 SQL (0) | 2021.09.16 |
| [Database] 02 - 4 무결성 제약조건 (0) | 2021.09.14 |




댓글